Weakly Supervised Referring Video Object Segmentation with Object Centric Pseudo Guided Learning
Abstract
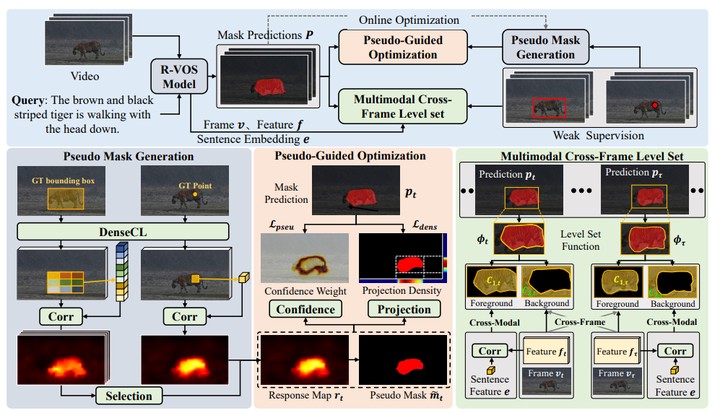
Referring video object segmentation (RVOS) is an emerging task for multimodal video comprehension while the expensive annotating process of object masks restricts the scalability and diversity of RVOS datasets. To relax the dependency on expensive mask annotations and take advantage from large-scale partially annotated data, in this paper, we explore a novel extended RVOS task, namely weakly supervised referring video object segmentation (WRVOS), which employs multiple weak supervision sources, including object points and bounding boxes. Correspondingly, we propose a unified WRVOS framework. Specifically, an object-centric pseudo mask generation method is introduced to provide effective shape priors for the pseudo guidance of spatial object location. Then, a pseudo-guided optimization strategy is proposed to effectively optimize the object outlines in terms of spatial location and projection density with a multi-stage online learning strategy. Furthermore, a multimodal cross-frame level set evolution method is proposed to iteratively refine the object boundaries considering both temporal consistency and cross-modal interactions. Extensive experiments are conducted on four publicly available RVOS datasets, including A2D Sentences, J-HMDB Sentences, Ref-DAVIS, and Ref-YoutubeVOS. Performance comparison shows that the proposed method achieves state-of-the-art performance in both point-supervised and box-supervised settings.Weikang Wang, Yuting Su, Jing Liu, Wei Sun, Guangtao Zhai. Weakly Supervised Referring Video Object Segmentation with Object Centric Pseudo Guided Learning, IEEE Transactions on Multimedia.