TANet: Target Attention Network for Video Bit-Depth Enhancement
Abstract
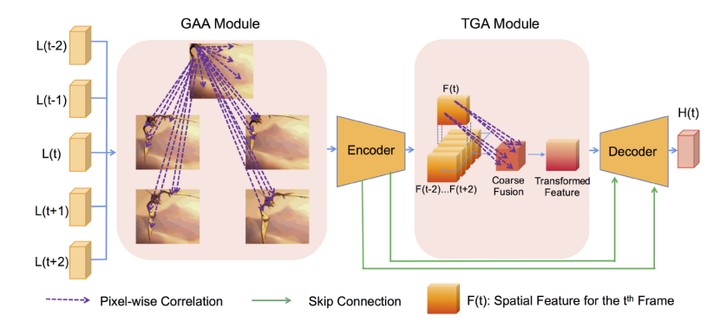
Video bit-depth enhancement (VBDE) reconstructs high-bit-depth (HBD) frames from a low-bit-depth (LBD) video sequence. As neighboring frames contain a considerable amount of complementary information related to the center frame, it is vital for VBDE to exploit neighboring frames as much as possible. Conventional VBDE algorithms with explicit alignment across frames attempt to warp each neighboring frame to the center frame with estimated optical flow, taking into account only pairwise correlation. Most spatiotemporal fusion approaches involve direct concatenation or 3D convolution and treat all features equally, failing to focus on information related to the center frame. Therefore, in this paper, we introduce an improved nonlocal block as a global attentive alignment (GAA) module, which takes the whole input video sequence into consideration to capture features that are globally correlated, to perform implicit alignment. Furthermore, given the bulk of features extracted from the center and neighboring frames, we propose target-guided attention (TGA). TGA can exploit more center-frame-related details and facilitate feature fusion. The proposed network (dubbed TANet) is capable of effectively eliminating false contours and recovering the center frame in high quality, as demonstrated by the experimental results. TANet outperforms state-of-the-art models in terms of both PSNR and SSIM with low time consumption.Jing Liu, Ziwen Yang, Yuting Su, Xiaokang Yang: TANet: Target Attention Network for Video Bit-Depth Enhancement. IEEE Trans. Multim. 24: 4212-4223 (2022)