Abstract
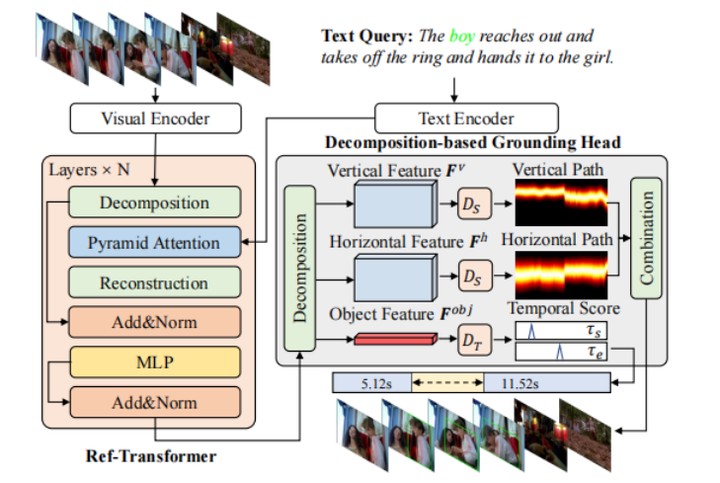
Spatio-temporal video grounding (STVG) aims to localize the spatio-temporal object tube in a video according to a given text query. Current approaches address the STVG task with end-to-end frameworks while suffering from heavy computational complexity and insufficient spatio-temporal interactions. To overcome these limitations, we propose a novel Semantic-Guided Feature Decomposition based Network (SGFDN). A semantic-guided mapping operation is proposed to decompose the 3D spatio-temporal feature into 2D motions and 1D object embedding without losing much object-related semantic information. Thus, the computational complexity in computationally expensive operations such as attention mechanisms can be effectively reduced by replacing the input spatio-temporal feature with the decomposed features. Furthermore, based on this decomposition strategy, a pyramid relevance filtering based attention is proposed to capture the cross-modal interactions at multiple spatio-temporal scales. In addition, a decomposition-based grounding head is proposed to locate the queried objects with less computational complexity. Extensive experiments on two widely-used STVG datasets (VidSTG and HC-STVG) demonstrate that our method enjoys state-of-the-art performance as well as less computational complexity. Weikang Wang, Jing Liu, Yuting Su, Weizhi Nie:Efficient Spatio-Temporal Video Grounding with Semantic-Guided Feature Decomposition. ACM Multimedia (MM). 4867–4876 (2023).