Sequence as a Whole: A Unified Framework for Video Action Localization With Long-Range Text Query
Abstract:
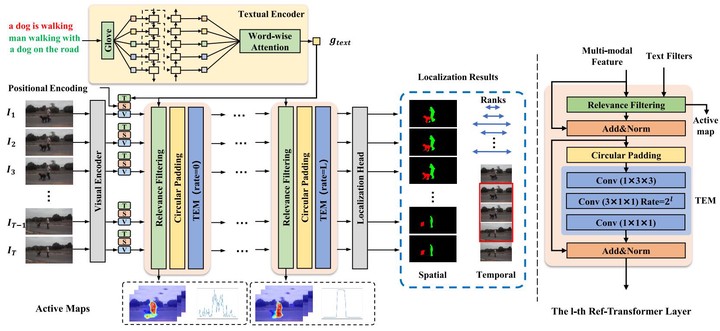
Comprehensive understanding of video content requires both spatial and temporal localization. However, there lacks a unified video action localization framework, which hinders the coordinated development of this field. Existing 3D CNN methods take fixed and limited input length at the cost of ignoring temporally long-range cross-modal interaction. On the other hand, despite having large temporal context, existing sequential methods often avoid dense cross-modal interactions for complexity reasons. To address this issue, in this paper, we propose a unified framework which handles the whole video in sequential manner with long-range and dense visual-linguistic interaction in an end-to-end manner. Specifically, a lightweight relevance filtering based transformer (Ref-Transformer) is designed, which is composed of relevance filtering based attention and temporally expanded MLP. The text-relevant spatial regions and temporal clips in video can be efficiently highlighted through the relevance filtering and then propagated among the whole video sequence with the temporally expanded MLP. Extensive experiments on three sub-tasks of referring video action localization, i.e., referring video segmentation, temporal sentence grounding, and spatiotemporal video grounding, show that the proposed framework achieves the state-of-the-art performance in all referring video action localization tasks. The code has been available at.